



Comme vous le savez sûrement, il existe un certain nombre de règles à respecter pour avoir un code clean, si je devais en citer qu’une seule ça serait DRY:
Do not Repeat Yourself.
Elle est simple à comprendre c’est vrai, mais la mettre en pratique ne l’est pas pour autant. je supposes que vous ne voyez pas la relation entre les AWS lambdas et le clean code et que vous vous demandez pourquoi je vous en parles alors que ce n’ai pas le sujet n’est ce pas?
C’est simple, parce qu’elle fait partie des règles dont on doit se rappeler chaque jour :), j’en ai donc profité pour vous montrer comment la mettre en place en utilisant les lambdas.
Pour ceux qui ne le savent pas, une AWS lambda est l’un des services AWS qui nous permet d’écrire un bout de code pour effectuer une fonctionnalité bien précise (on peut donc voir ça comme une méthode). Après l’avoir déclenché une machine lui sera alloué sans pour autant l’avoir configurer au préalable, on est sur ce qu’on appelle du “Serverless”.
C’est un framework qui répond à un besoin simple, comment développer et tester ses lambdas localement ?
il suffit de créer un fichier Template (YAML ou JSON), dans lequel on fera la description de nos différentes ressources.
J’expliques tout ça en détail dans l’article suivant :
https://medium.com/@AmineVolk/initiation-aux-services-web-amazon-8c83eff47a72
Supposons maintenant que nous ayons plusieurs lambdas qui partagent la même logique métier, par exemple une application de gestion des utilisateurs,
on aura donc plusieurs actions qui vont se répéter à savoir : AddUser(), deleteUser()…etc
il faut savoir qu’une fois notre lambda packager et déployer celle-ci sera zipée et donc si vous essayez d’accéder à un fichier qui est au dessus de la racine du répertoire de la lambda, vous n’y arriverez pas.
Exemple :
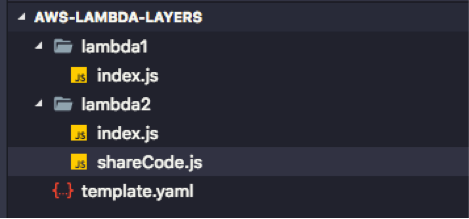
Dans cet exemple la lambda1 ne pourra pas accéder au shareCode car comme je les expliqué précédemment elle sera zipée.
Mais si on se réfère aux bonnes pratiques d’après l’abstract principle
Un bout de code doit apparaître une seule fois dans le code source.
C’est là qu’intervient la lambda layer qui va nous permettre justement d’encapsuler le code partagé entre les différentes lambdas afin que ces
dernières puissent y accéder.
On peut aussi l’utiliser pour mettre nos dépendances, par exemple si vous développez avec nodejs et que vous avez les mêmes modules utilisés dans
toutes les lambdas vous pouvez donc les mettre dans la lambda layers, comme ça vos lambda seront plus légères lors de leurs déploiement.
Les lambda layers ont été introduite en décembre 2018, il faut donc mettre à jour son AWS cli et SAM cli.
Au moment où j’écrivais cet article j’avais la config suivante :
Pour mettre à jour votre aws cli, vous devez aussi avoir au moins python3, si ce n’est pas le cas exécutez les commandes suivantes :
apt-get install python3-dev — assume-yes
apt-get -y install python3-pip
python3.7 -m pip install awscli — upgrade
Pour mettre à jour votre sam cli :
npm update -g aws-sam-local
Lors de son déploiement la lambda layer sera zippée comme pour toute lambda, mais celle-ci aura la particularité d’être accessible par les autres
lambdas.
Sur Amazon, la lambda layers sera mise dans un répertoire /opt, dans lequel les autres lambdas vont chercher le code partagé.
Par contre, dans notre environnement local avec SAM, la lambda layer sera téléchargée puis packagée dans un container.
Je vais créer dans l’exemple suivant une lambda layer dans laquelle on aura un code qui sera utilisé par une autre lambda.
Arborescence du dossier de la layer (nodejs) :
0n va utiliser nodejs, et il faut savoir qu’on doit respecter une certaine arborescence pour que le code partagé dans la layer soit accessible par les autres lambdas, dans le cas contraire ça ne marchera pas.
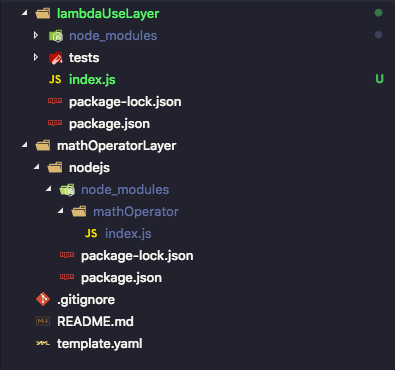
il ne faut pas oublier d’inclure notre layer dans les dossiers à ne pas ignoré par git :

Description des 2 lambda dans le Template.yaml
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Resources:
lambdaUseLayer:
Type: AWS::Serverless::Function
Properties:
CodeUri: lambdaUseLayer/
Handler: index.lambdaHandler
FunctionName: lambdaUseLayer
Runtime: nodejs8.10
Layers:
- !Ref mathOperatorLayer
Policies:
- AWSLambdaBasicExecutionRole
Events:
Whoami:
Type: Api
Properties:
Path: /test/{operation}
Method: post
mathOperatorLayer:
Type: AWS::Serverless::LayerVersion
Properties:
LayerName: mathOperatorLayer
Description: create mathOperator layers
ContentUri: mathOperatorLayer/
CompatibleRuntimes:
- nodejs8.10
RetentionPolicy: RetainOn voit qu’il n’y a pas une grande différence entre les 2 lambdas, il suffit de mettre le type LayerVersion et ContentUri au lieu de CodeUri
pour la layer.
Pour spécifier dans notre lambda l’utilisation de la layer, on l’a mis en référence car elle se trouve dans le même projet, sinon on aurait mis
son ARN.
Notre layer :
const addition = (a, b) => {
return a + b;
};
const subtraction = (a, b) => {
return a - b;
};
module.exports = { addition, subtraction };On va créer une lambda layer simple :
const { addition, subtraction } = require("mathOperator");
exports.lambdaHandler = (event, context, callback) => {
let body = JSON.parse(event.body);
const operation = event.pathParameters.operation;
let result;
if (operation) {
if (operation === "addition") {
result = addition(body.a, body.b);
} else if (operation === "substraction") {
result = subtraction(body.a, body.b);
}
sendResponse(200, { result: result }, callback);
} else {
sendResponse(500, { message: "internal error" }, callback);
}
};
function sendResponse(statusCode, message, callback) {
const response = {
statusCode: statusCode,
body: JSON.stringify(message)
};
callback(null, response);
}Vous remarquerez que l’import d’une layer se fait comme tout autre module.
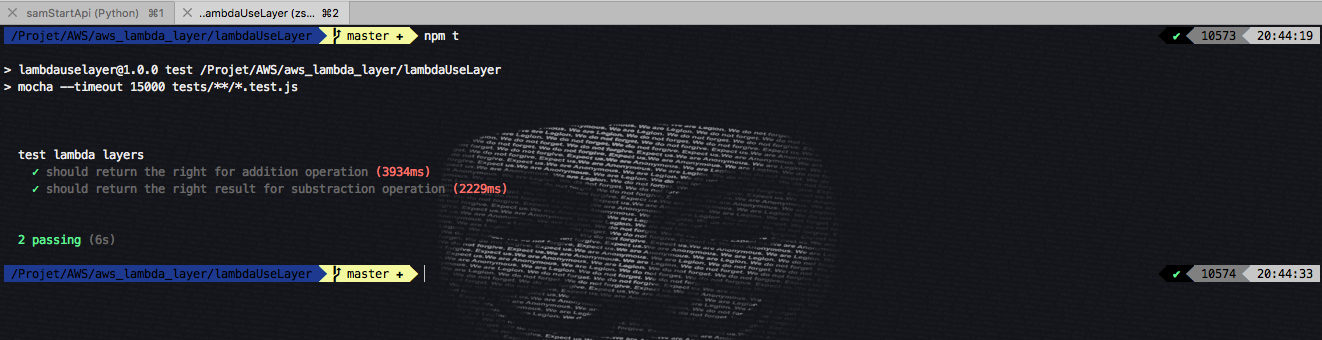
Même si le code est très simple, un test s’impose :
const request = require("supertest");
const host = process.env.HOST || "https://localhost:3000";
const expect = require("chai").expect;
describe("test lambda layers", () => {
it("should return the right for addition operation", done => {
request(`${host}`)
.post("/test/addition")
.send({ a: 3, b: 5 })
.expect(200)
.expect(res => {
expect(res.body).deep.eq({ result: 8 });
})
.end(done);
});
it("should return the right result for substraction operation", done => {
request(`${host}`)
.post("/test/substraction")
.send({ a: 7, b: 2 })
.expect(200)
.expect(res => {
expect(res.body).deep.eq({ result: 5 });
})
.end(done);
});
});
view raw
On voit bien que tout s’est bien passé.
Déploiment sur AWS :
packager notre projet et l’envoyer vers un bucket S3 :
sam package --template-file template.yaml --output-template-file ./serverless-output.yaml --s3-bucket nomDeVotreBucket
Déploiement de notre stack :
aws cloudformation deploy --template-file serverless-output.yaml --stack-name nomDeVotreStack --capabilities CAPABILITY_IAM;
Si tout se passe bien, on peut remarquer la création de la stack pour notre layer

Dans
cet article, je vous ai montré comment implémenter une layer que ce
soit dans le même projet ou dans un tout autre, j’ai volontairement
utilisé des exemples très simples, afin de vous montrer les étapes à
suivre sans pour autant dépendre d’une techno particulière.