



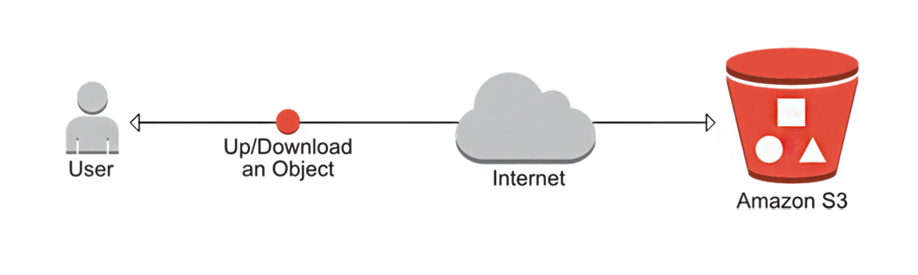
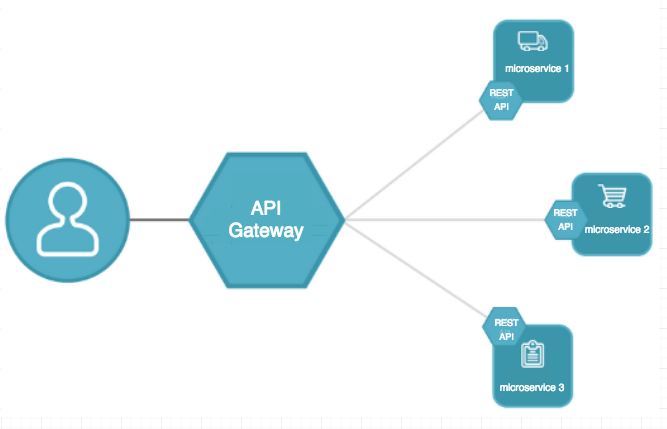
Ne vous inquiétez pas, on ne va pas parler de mathématique, mais plutôt d’un service web Amazon trés répandu, il va nous permettre la mise en place d’une architecture dite “ serverless”.
Concrètement une lambda est une fonction qui va répondre à un besoin bien précis, c’est tout à fait normal car une fonction est censée faire qu’une seul chose!
Une classe ou une méthode doit faire une seule chose, elle doit la faire bien et ne faire qu’elle
Pour déclencher une lambda nous avons une panoplie de choix, les plus utilisés sont les suivants :

La structure d’une lambda :
exports.lambdaHandler = (event, context, callback) => {
const response = {
statusCode: 200,
body: JSON.stringify(`Azul !`)
};
callback(null, response);
};La structure d’une lambda :
On doit déclarer une fonction qui va recevoir 3 objets : event, context et callback, et cette méthode sera le point d’entrée de la lambda.
l’event va nous permettre de récupérer plusieurs informations importantes :
Callback : on l’utilise pour renvoyer une réponse.
Nous avons vu API geteway qui nous permet de déclencher une lambda qui va exécuter un certain nombre de traitements, on va passer maintenant au moyen de stocker nos infos.
C’est une base de données NoSql (not only sql) orientée documents, et contrairement au model relationnel on a pas de structure rigide à
suivre, à part un Id pour identifier nos document.
En mélangeant les lambdas, API Gateway et dynamodb on peut arriver à quelque chose de très intéressant :
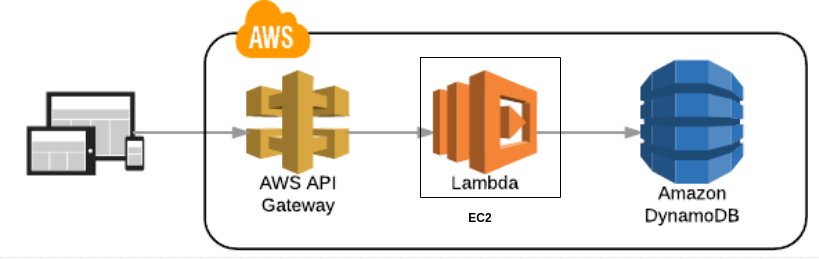
On va implémenter juste en-dessous un exemple complet, qui respecte cette archi, mais avant cela on doit parler d’un autre service aussi important.
C’est grâce à ce service que nous allons décrire les ressources qui seront crées par Amazon, cela se fait de manière très simple à travers un fichier YAML ou JSON.
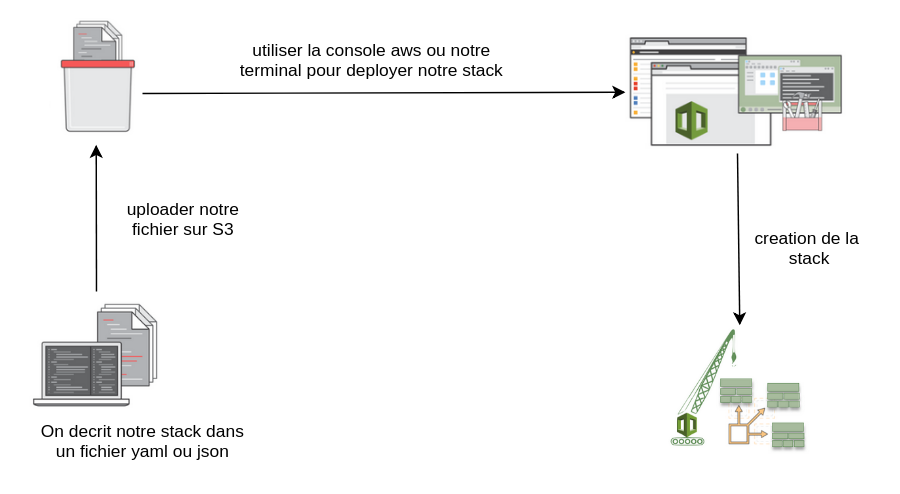
Les avantages de coudFormation :
Par contre une question se pose :
Aprés avoir crée une application, faut-il relancer le processus à chaque fois que je désire tester une nouvelle fonctionnalité ?
Cette question est pertinente car de un on perd beaucoup de temps à faire tout cela, et de deux les ressources sur AWS sont payantes à l’utilisation, et vue que le temps c’est de l’argent..
C’est un framework qui vient répondre à la problématique précédente, à savoir comment développer et tester des applications severless localement.
SAM est une extension du service cloudFormation qui permet la description des ressources mais pas leur exécution localement. Pour rajouter cette fonctionnalité SAM s’appuie essentiellement sur docker, en créant un container qui simule l’environnement AWS.
On va passer aux commandes de base pour utiliser SAM. commençons par son installation :
pip install --upgrade pip
pip install --upgrade setuptools
pip install --upgrade aws-sam-cli
Pour packager notre code, et l’envoyer dans S3 :
sam package --template-file template.yaml --output-template-file ./serverless-output.yaml --s3-bucket bucketName
Explication :
Déployer :
aws cloudformation deploy --template-file serverless-output.yaml --stack-name stack-article --capabilities CAPABILITY_IAM
Explication :
Pour lancer notre api localement :
sam local start-api --skip-pull-image
On peut aussi verifier la validité de notre template avec :
sam validate
on doit se positionner dans le dossier où se trouve notre fichier.
On va créer une lambda qui sera déclenchée par l’appel à la methode GET sur un endpoint.
On aura l’organisation suivante :
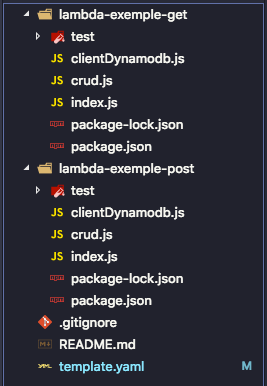
Notre fichier template :
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: >
eaprofile
Sample SAM Template
Globals:
Function:
Timeout: 30
Resources:
ApiGatewayExample:
Type: AWS::Serverless::Api
Properties:
StageName: prod
DefinitionBody:
swagger: "2.0"
info:
title:
Ref: AWS::StackName
description: My API getway exapmle
version: 1.0.0
paths:
/user/{user}:
get:
x-amazon-apigateway-integration:
httpMethod: post
type: aws_proxy
uri:
Fn::Sub: arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${LambdaExampleGet.Arn}/invocations
/user:
post:
x-amazon-apigateway-integration:
httpMethod: post
type: aws_proxy
uri:
Fn::Sub: arn:aws:apigateway:${AWS::Region}:lambda:path/2015-03-31/functions/${LambdaExamplePost.Arn}/invocations
LambdaExampleGet:
Type: AWS::Serverless::Function
Properties:
Runtime: nodejs8.10
Handler: index.lambdaHandler
CodeUri: lambda-exemple-get
FunctionName: LambdaExampleGet
Environment:
Variables:
DYNAMODB_TABLE: !Ref ExampleTable
Policies:
- AWSLambdaBasicExecutionRole
- AmazonDynamoDBReadOnlyAccess
LambdaExamplePost:
Type: AWS::Serverless::Function
Properties:
Runtime: nodejs8.10
Handler: index.lambdaHandler
CodeUri: lambda-exemple-post/
FunctionName: LambdaExamplePost
Environment:
Variables:
DYNAMODB_TABLE: !Ref ExampleTable
Policies:
- AWSLambdaBasicExecutionRole
- AmazonDynamoDBFullAccess
ExampleTable:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: id
AttributeType: S
KeySchema:
- AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
ConfigLambdaPermissionForApiGetwayToInvokeLambdaExampleGet:
Type: "AWS::Lambda::Permission"
DependsOn:
- ApiGatewayExample
- LambdaExampleGet
Properties:
Action: lambda:InvokeFunction
FunctionName: !Ref LambdaExampleGet
Principal: apigateway.amazonaws.com
ConfigLambdaPermissionForApiGetwayToInvokeLambdaExamplePost:
Type: "AWS::Lambda::Permission"
DependsOn:
- ApiGatewayExample
- LambdaExamplePost
Properties:
Action: lambda:InvokeFunction
FunctionName: !Ref LambdaExamplePost
Principal: apigateway.amazonaws.comNous avons déclaré 4 type de ressources :
Les permissions :
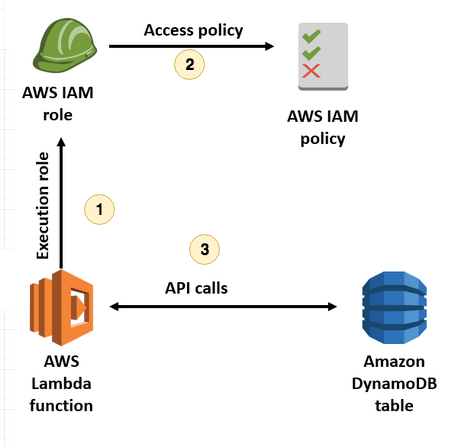
Amazon permet une gestion de sécurité très flexible, on est sur du “security as code”, au
départ nos ressources ne peuvent presque rien faire, puis on doit leur
affecter des accès suivant leur champs d’actions, le but est de leur
donner juste ce qu’il faut pour qu’elle effectuent leurs traitements.
Dans
notre cas on a donné le droit d’accésen lecture sur dynamodb pour notre
lambda qui fait un GET lambda (49–51) et un accés total celle qui
effectue un POST (63–65).
Amazon
nous permet d’aller très loin pour tout ce qui concerne la gestion de
la sécurité, dans notre exemple on peut même spécifier à notre lambda
quelle table manipuler par exemple.
Pour ceux qui veulent approfondir : https://aws.amazon.com/fr/iam/
API gateway : on
l’a défini entre la ligne 12 et 37 et cela en déclarant une ressource
avec un type AWS::Serverless::Api. Puis on a précisé quelles sont les
endpoints qui seront capturés par cette gateway et cela en utilisant le
mot clé paths(23), nous en avons déclaré 2, et chaqu’un déclanche une
lambda :
Avant de commancer la partie qui traite des lambdas on doit faire un pull de 2 image docker :
La première concerne notre environnement de dev nodejs :
docker pull lambci/lambda:nodejs8.10
La deuxième concerne notre base dynamodb :
docker pull amazon/dynamodb-local
On doit biensur la lancer avec :
docker run -p 8000:8000 amazon/dynamodb-local
Lambda :
Passons maintenant à la partie la moins barbante, c’est a dire le code !
On va commencer par la lambda qui nous permet de créer un user :
Nous avons besoin d’un client dynamodb afin de nous y connecter :
const AWS = require("aws-sdk");
const awsRegion = process.env.AWS_REGION || "us-east-2";
var makeDynamodbClient;
var client;
var options = {
region: awsRegion
};
if (process.env.TEST) {
options.endpoint = "https://localhost:8000";
client = new AWS.DynamoDB(options);
}
if (process.env.AWS_SAM_LOCAL) {
options.endpoint = "https://dynamodb:8000";
}
makeDynamodbClient = () => {
return new AWS.DynamoDB.DocumentClient(options);
};
module.exports = { makeDynamodbClient, client };j’ai crée un simple fichier qui nous permet d’ajouter et de récupérer un user sur notre base :
const TABLENAME = process.env.DYNAMODB_TABLE || "ExampleTable";
const { makeClient } = require("./clientDynamoDB");
const clientDynamoDB = makeClient();
const getUser = id => {
var params_for_search = {
TableName: TABLENAME,
KeyConditionExpression: "#id = :idValue",
ExpressionAttributeNames: {
"#id": "id"
},
ExpressionAttributeValues: {
":idValue": id
}
};
return new Promise((resolve, reject) => {
clientDynamoDB.query(params_for_search, function(err, data) {
if (err) {
reject(err);
} else {
if (data.Items.length == 0) {
resolve(data.Items);
} else {
resolve(data.Items);
}
}
});
});
};
const addUser = user => {
var profileToAdd = {
TableName: TABLENAME,
Item: user
};
return new Promise((resolve, reject) => {
clientDynamoDB.put(profileToAdd, function(err, data) {
if (err) {
reject(err);
} else {
resolve(true);
}
});
});
};
module.exports = { getUser, addUser };Notre lambda qui permet de créer un user :
const crud = require("./crud");
exports.lambdaHandler = (event, context, callback) => {
console.log("****** loading lambdaPost");
console.log("****** event.body : "+JSON.stringify(event.body));
const user = JSON.parse(event.body);
console.log(`the user to add : ${JSON.stringify(user)}`);
crud
.addUser(user)
.then(response => {
if (response) {
sendResponse(
200,
{ message: "user added successfuly", user: user },
callback
);
}
})
.catch(err => {
sendResponse(500, `err ${err} failed to add ${user}`, callback);
});
};
function sendResponse(statusCode, message, callback) {
const response = {
statusCode: statusCode,
body: JSON.stringify(message)
};
callback(null, response);
}
Récupérer un user :
const crud = require("./crud");
exports.lambdaHandler = (event, context, callback) => {
const id = event.pathParameters.user;
crud
.getUser(id)
.then(response => {
console.log("response : "+response);
sendResponse(200, response, callback);
})
.catch(err => {
console.error(`get failed ${err}`);
});
};
function sendResponse(statusCode, message, callback) {
const response = {
statusCode: statusCode,
body: JSON.stringify(message)
};
callback(null, response);
}Comme
indiqué ci-dessus l’objet event nous permet de récupérer plusieurs
informations, dans notre cas on a récupéré l’ id utilisé dans le path
lors de son invocation.
Pour renvoyer une réponse on utilise la méthode callback, dans la quelle on lui passe un JSON qui contient un status, un body et optionnellement un header.
Pour tester nos lambda on doit d’abord lancer notre API :
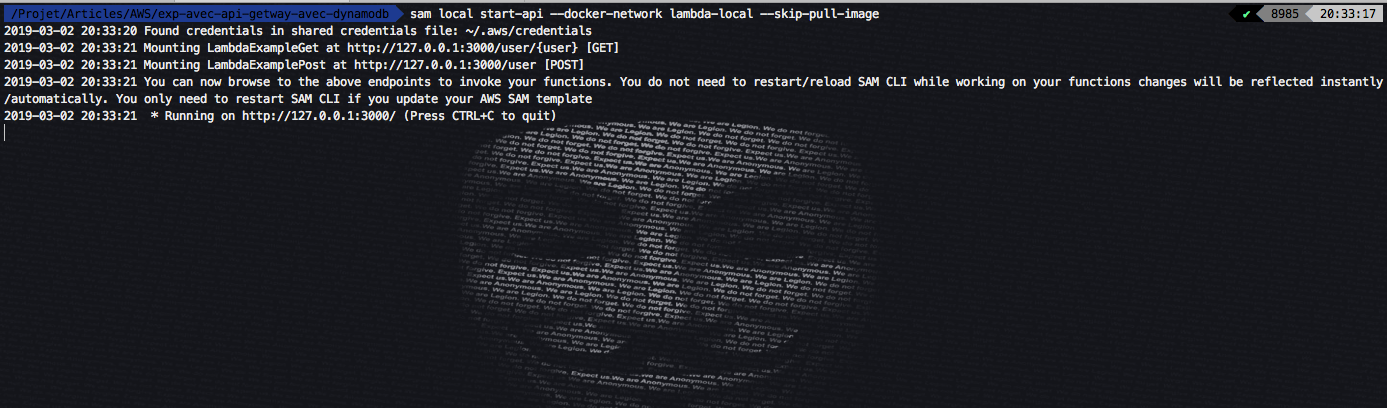
Nous allons créer un simple test pour l’ajout et la récupération d’un user :
Test de création d’un user :
var request = require("supertest");
var expect = require("chai").expect;
var host = process.env.HOST || "https://localhost:3000";
describe("Test create user", () => {
const userToAdd = {
id: "1",
name: "Amine",
pseudo: "Volk"
};
it("Should create user", done => {
request(`${host}`)
.post("/user")
.send(userToAdd)
.expect(200)
.expect(res => {
expect(res.body).deep.eq({
message: "user added successfuly",
user: userToAdd
});
})
.end(done);
});
});Après exécution on aura :
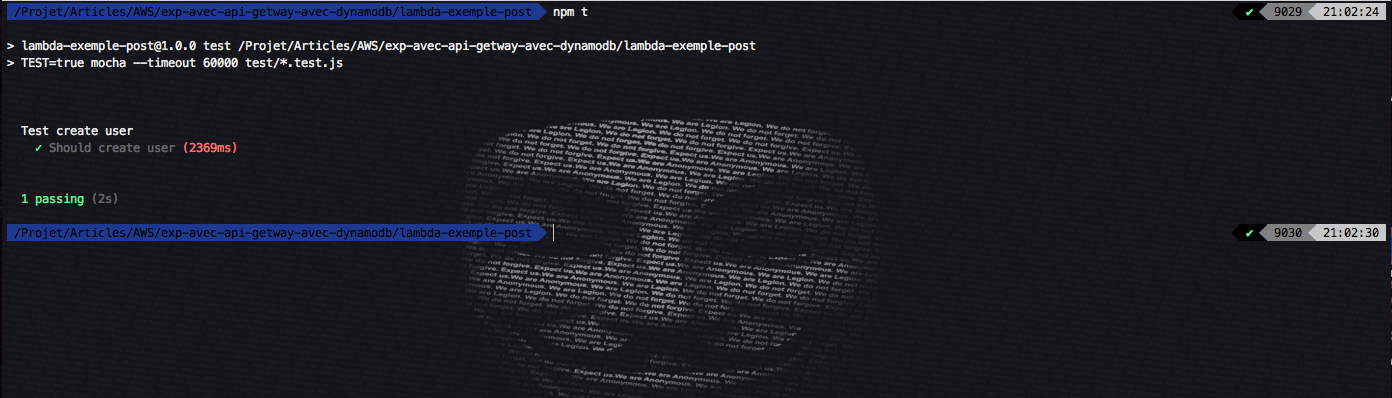
Nous allons récupérer le user que nous avons crée précédemment :
var request = require("supertest");
var expect = require("chai").expect;
var host = process.env.HOST || "https://localhost:3000";
describe("Test retreave user", () => {
const userToFetch = {
id: "1",
name: "Amine",
pseudo: "Volk"
};
it("Should retreave user", done => {
request(`${host}`)
.get("/user/1")
.expect(200)
.expect(res => {
expect(res.body[0]).deep.eq(userToFetch);
})
.end(done);
});
});Dans
la ligne 16 j’ai utilisé body[0] car dynamodb renvoi les résultats dans
un tableau, et comme on fait un get sur un seul élément on prend le
premier.
On aura le resultat suivant :

Voilà,
on arrive à la fin de cette présentation, dans laquelle j’ai essayé de
vous donner une vue globale sur quelques web service d’Amazon, j’éspere
qu’elle vous a plu, je vous dis chaw 😉
ci-dessous le lien vers le repo Github :
https://github.com/AmineVolk/Initiation-aux-services-web-Amazon